
This blog is an art project. Mia’s identity and all written and visual content on this website have been generated using AI tools. Mia’s blog is a multi-layered dream by a computer, starting with the creation of her personality and ending with a snapshot painting of her trip that never happened.
This blog project also allowed me to experiment with scalable content production. It consists of 1000 blog posts about 1000 random towns around the world, each accompanied by a watercolor painting depicting a scene during her visit.
I wrote a Python script that takes in a CSV file of cities (+country) and their geo coordinates and returns a CSV file with a blog post and an article image that can be directly uploaded to WordPress. In this post, I want to quickly walk you through how I set this up so you can apply what I learned to your content/SEO project.
If you have questions about this project, hit me up on Linkedin.
The SEO-Experiment
The blog project started as an SEO competition with a friend. Whoever can generate more organic clicks to a newly set up website & domain within three months wins. There is so much talk about the dos and don’ts of AI-aided content generation that I decided to try a truly scaled approach myself.
My core assumption is that due to drastically decreased marginal cost in content production, the long tail becomes attractive, at least for some time.
I decided to go for a travel blog about small cities for the following reasons:
- There is well-structured, freely available data on all cities with >1000 inhabitants
- There is likely little competition from travel bloggers for these small towns
- I assume that any place with a population of 10k has some search volume for the name of the town
- The city data can easily be augmented with other data from the web (in this case, via the Google Maps API)
- Travel stories are reports of subjective experiences, so even if they never happened, they are less prone to be “wrong” than knowledge articles.
I did not validate my assumptions much and just decided to go for it. Validation will come over time in the form of traffic (or not).
I am curious to see whether Google will detect that this website is effectively spam and how long that will take. I will update this page with screenshots from the Google search console.
Providing context and background knowledge to the LLM
As mentioned above, the inputs for my script are cities, their country, and their geocoordinates. To achieve both consistency (think brand voice) and variability of the blog posts, it is important to add additional context and information for the LLM to work with.
Augmenting with real-world data via Google Maps API
I retrieve the best-rated restaurant and the best-rated attraction for each location to make the stories more authentic using the Google Maps API. This also helps to structure the stories and the place names double as secondary SEO keywords for the articles.
Adding in variables and background information
If you have tried, you know that LLMs will always generate something, but not always what you want. So if I prompted “Write a travel blog about XYZ” the result would be generic.
This is why I introduced some other variables. E.g. I let ChatGPT generate a personality and personal background for Mia that is always included in the prompts for new blog posts. In a corporate context, this could be your brand identity.
Name: Mia Carter
Age: 28
Nationality: Canadian
Ethnic Background: Mixed Irish and Japanese
Languages Spoken: English, French, basic Japanese
Education Background: B.A. in Journalism
Previous Professions: Freelance writer, barista
Hobbies: Photography, watercolour painting on her ipad, urban sketching
...I also wanted to make sure there is some variation between the posts. So I asked ChatGPT to generate 40 unforeseen events that could happen to someone who is traveling, like these:
...
You lost your way in a new city, leading to an unplanned adventure.
You had a memorable encounter with wildlife.
You tried a local dish that didn't agree with you.
You participated in a local workshop or craft session.
You missed a flight due to traffic or timing error.
...One of the events is included in the prompt for a new blog post every time. The same goes for 5 story archetypes, also provided by ChatGPT:
The Quest: You embark on a journey with a specific goal or destination in mind, be it a physical place, a cultural experience, or a personal achievement.
Overcoming the Monster: You face a significant challenge or obstacle during your travels, which could be an internal struggle, like overcoming fear, or an external problem, such as dealing with a difficult situation.
...Automated content generation
I am adding the entire script I created at the end of this post.
This summarizes the various steps: The script performs a sequence of operations on data from a CSV file, involving external APIs and text/image generation. Here’s a concise step-by-step breakdown:
- Load API Keys: Retrieves OpenAI and Google API keys from text files.
- Process CSV Data:
- Opens a CSV file (‘db.csv’) for reading and another (‘db_new.csv’) for writing.
- Iterates through the rows of the input CSV file.
- Data Enrichment and Content Generation:
- For each row (up to 1000), it performs the following steps:
- Update Restaurant Information: Adds information about the highest-rated nearby restaurant using Google Places API.
- Update Tourist Attraction Information: Adds details of a top-rated tourist attraction, also via Google Places API.
- Generate Blog Post: Creates a travel blog post using OpenAI’s GPT model. This post is based on random story arcs and events, and includes details from the current row (like town, country, restaurant, and attraction).
- Generate Image Prompt: Uses OpenAI’s GPT model to generate a text prompt for an image, based on the generated blog post.
- Download and Convert Image: Generates an image using OpenAI’s DALL-E model based on the prompt, downloads it, converts it to WebP format, and saves it with a filename based on the row’s ID and town.
- For each row (up to 1000), it performs the following steps:
- Write Updated Data: The script writes the enriched and updated data to ‘db_new.csv’.
This script integrates data enrichment, AI-driven content creation, and image processing, showcasing a sophisticated automation of content generation and enhancement.
What did it cost?
Generating all articles and images cost about $30.92 for the API usage. Most of it went into generating images with Dall-E 2. For most texts I used GPT 3.5 because it’s cheaper (and faster).
On Jan 18, I switched to GPT4 for the article generation of about 100 articles; you can see how it is much more expensive than GPT3.5.
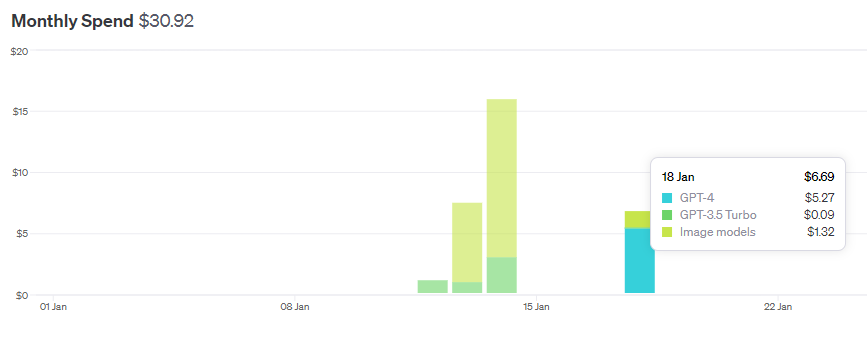
All in all, one blog post cost me about $0.03. Using GPT4, one post would cost around $0.07.
The Google Maps API is surprisingly expensive, but when you sign up for the first time, you get a few hundred dollars in free cloud credit, so that was covered. Also, you only have to pay for the API when you exceed a $200 usage threshold per month and it wouldn’t have been that much in my case.
The domain and hosting are free with strato.de for the first year, and they even provide pre-installed WordPress, which is nice not to waste time on setting that up.
The Script
Note: The script requires several input files for its operations:
- API Key Files:
google-api.txt: Contains the Google API key for accessing Google Places API.openai-api.txt: Contains the OpenAI API key for accessing GPT and DALL-E models.
- CSV Files:
db.csv: The main database file. It’s the source CSV file containing rows of data that the script processes.
- Additional Text Files for Content Generation:
story-arc: A file containing various story arcs used for generating blog posts.events: A file with different events to incorporate into the blog posts.persona: Contains information about a persona used to shape the style and content of the generated blog posts.
import openai
import csv
import random
import requests
from PIL import Image
import os
def load_api_key(filename):
# Load the OpenAI API key from a file.
with open(filename, 'r') as file:
return file.read().strip()
def select_random_items(story_arc_file, events_file):
# Load story arcs from the file
with open(story_arc_file, 'r', encoding='utf-8') as file:
story_arcs = file.readlines()
# Load events from the file
with open(events_file, 'r', encoding='utf-8') as file:
events = file.readlines()
# Select a random story arc and event
random_story_arc = random.choice(story_arcs).strip()
random_event = random.choice(events).strip()
return random_story_arc, random_event
def get_highest_rated_place(lat, lng, api_key, place_type):
base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
params = {
"location": f"{lat},{lng}",
"radius": "3000",
"type": place_type,
"key": api_key
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
results = response.json().get("results", [])
if results:
rated_places = [res for res in results if "rating" in res]
if rated_places:
highest_rated = max(rated_places, key=lambda x: x['rating'])
return highest_rated.get("name")
return 0
def update_list_with_restaurant(row, api_key):
lat, lng = row[3].split(", ") # Assuming coordinates are at index 3
row[4] = get_highest_rated_place(lat, lng, api_key, "restaurant")
return row
def update_list_with_attraction(row, api_key):
lat, lng = row[3].split(", ") # Assuming coordinates are at index 3
row[5] = get_highest_rated_place(lat, lng, api_key, "tourist_attraction")
return row
def generate_blog_post(row, story_arc_file, events_file, persona_file, client):
# Load story arc and event
random_story_arc, random_event = select_random_items(story_arc_file, events_file)
# Load persona info
with open(persona_file, 'r', encoding='utf-8') as file:
persona_info = file.read()
# Extract town details from the row list
town = row[1] # Assuming town name is at index 1
country = row[2] # Assuming country is at index 2
restaurant = row[4] # Assuming restaurant is at index 4
attraction = row[5] # Assuming attraction is at index 5
# Create the user message
user_msg = f"Write a travel blog post about visiting the town {town}, {country} in 700 words. " \
f"During your visit, {random_event}. In {town} you visited the attraction {attraction} and the restaurant {restaurant}. " \
f"Let your personality and hobbies inform your story and your writing style." \
f"The text should be SEO optimized for your Travel Blog." \
f"Follow this story arc: {random_story_arc}." \
f"Do not provide a headline or title. Only include several sub headlines between paragraphs and format them as <h3>. Include the name of the town in the first headline." \
f"Avoid redundancy in your text and keep the language authentic." \
f"Include at least one piece of concrete useful advice for people visiting {town}." \
f"Include a sentence that relates your personality to the place you are visiting." \
f"Only provide the text as output, no comments." \
f"The text can include a few negative experiences, your tone is not overly positive and can be thoughtful, debating." \
f"Generally don't overdo it with superlatives and statements of life changes."
# Call OpenAI API
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Act as the travel blogger Mia. "
"You write your travel stories as if you were telling them to your best friend. Here is a list of your personality attributes:\n" + persona_info},
{"role": "user", "content": user_msg}
]
)
# Generate the blog post
blog_post_content = completion.choices[0].message.content
# Update the 'story' value in the original row list
row[6] = blog_post_content # Assuming the story is at index 6
return row
def generate_prompt(client, data_row):
try:
if data_row[7] != 3: # Check if 'prompt' value in data_row == 0
user_msg = f"Give a short one-sentence visual description of one particular situation in this text: {data_row[6]}." \
f"Only describe the image. Do not mention the text or the author."
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Act as an experienced image describer."},
{"role": "user", "content": user_msg}
]
)
prompt = completion.choices[0].message.content.strip() if completion.choices else "No prompt generated"
data_row[7] = prompt # Update the 'prompt' value in data_row with the generated response
except Exception as e:
print(f"Error processing data_row with ID {data_row[0]}: {e}")
data_row[7] = "Error generating prompt"
return data_row
def generate_and_download_image(data_row, client):
try:
id, town, country, coordinates, restaurant, attraction, story, prompt, image = data_row
if image != 3:
response = client.images.generate(
model="dall-e-2",
prompt=f"a monet-style watercolor painting of: {prompt}",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
# Ensure the /images directory exists
images_dir = 'images'
os.makedirs(images_dir, exist_ok=True)
# Create a filename using 'id' and 'name of town'
filename = f"{id}_{town.replace(' ', '_')}.jpg"
# Download and save the image
image_response = requests.get(image_url)
if image_response.status_code == 200:
with open(os.path.join(images_dir, filename), 'wb') as file:
file.write(image_response.content)
print(f"Image downloaded successfully as {filename}.")
# Convert the downloaded image to WebP format
webp_filename = f"{id}_{town.replace(' ', '_')}.webp"
img = Image.open(os.path.join(images_dir, filename))
img.save(os.path.join(images_dir, webp_filename), "webp")
print(f"Image converted to WebP format as {webp_filename}.")
# Update the 'image' value in data_row with the WebP filename
data_row[8] = webp_filename
else:
print(f"Failed to download the image for '{prompt}'.")
else:
print(f"Skipping image generation and download for '{prompt}' as 'image' value is 0.")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
google_api_key = load_api_key("google-api.txt")
OPENAI_API_KEY = load_api_key("openai-api.txt")
from openai import OpenAI
client = OpenAI(api_key=OPENAI_API_KEY)
with open('db.csv', 'r', encoding='utf-8') as infile, open('db_new.csv', 'a', newline='', encoding='utf-8') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
count = 0 # Counter for the number of rows processed
for row in reader:
if count == 0: # Skip the header row
writer.writerow(row) # Write the header row to the new file
count += 1
continue
if count <= 1000:
# Convert row to data_row list format
data_row = [row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8]]
print(data_row)
# Perform updates and processing on data_row
update_list_with_restaurant(data_row, google_api_key)
print(data_row)
update_list_with_attraction(data_row, google_api_key)
print(data_row)
generate_blog_post(data_row, 'story-arc', 'events', 'persona', client)
print(data_row)
data_row = generate_prompt(client, data_row)
print(data_row)
generate_and_download_image(data_row, client)
print(data_row)
writer.writerow(data_row)
count += 1 # Increment the counter after processing each row
else:
break # Stop the loop after processing 3 rows